Three out of ten
The last entry ended on a question I'd left myself. The tool ran and returned the fields, but whether they were the right fields was a separate thing, and I had no way to check. Returning something is not the same as returning the right thing. So before I trusted it, I wanted a way to actually know.
The way to know is boring, which is most of why it took me a while to do it. I picked ten real event pages and wrote down the correct answer for each one by hand. Title, date, time, lineup, price. I sat with each page and typed what was true. Two of those fields the tool didn't even return yet, so I had to teach it lineup and price before the eval was fair. Then I built a small script that runs all ten through the tool and lines up what comes back against what I'd written.
The part that matters is the order. I wrote the answer key first, before running the tool once. If you build the key out of the tool's own output, you aren't testing anything. You're asking the tool to agree with itself and calling that a pass. The key has to be what's true, decided on its own, even when that's slower and feels like not-working.
Then I ran it. Three out of ten correct, where correct means every field right. One wrong field and the page counts as a miss.
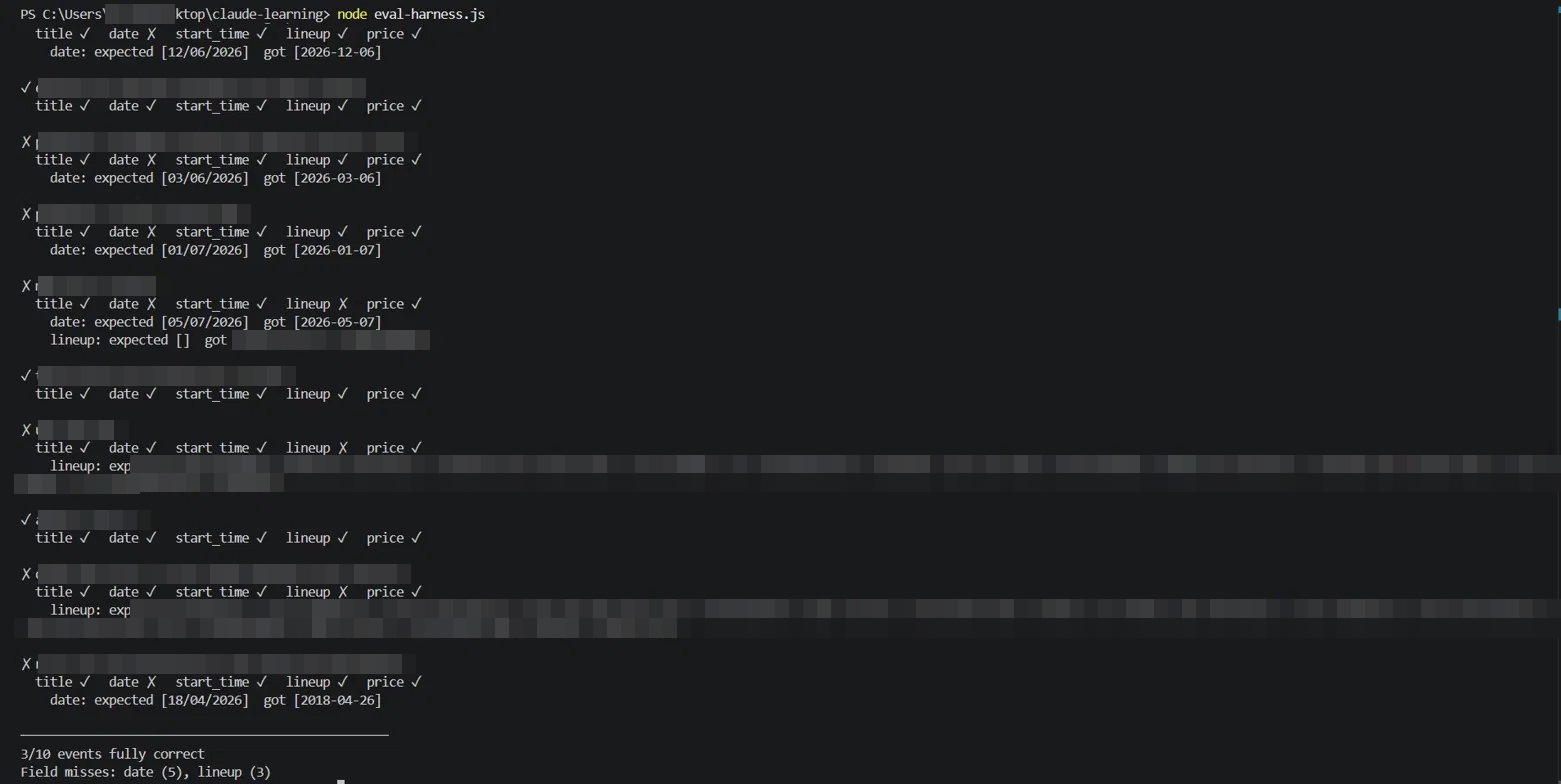
Here is the part worth sitting with. The seven wrong answers did not look wrong. A date, a time, a list of names, all plausible, all formatted properly, and most of them wrong anyway. That is the quiet problem with building on a model. It is easy to produce convincing output and call the job done, because convincing output is exactly what the model is good at. Whether the output is correct is a different question, and the only way I know to answer it is to check, one page at a time, against an answer you wrote yourself. The old me would have shipped this at three out of ten without ever knowing it was three out of ten.
Most of the misses were dates. The tool kept reading the day and the month in the wrong order, so the first of July came back as the seventh of January. One date was wrong in a stranger way I haven't worked out yet.
But the miss I keep thinking about wasn't the tool being wrong at all. On one page it returned a lineup, and my answer key said there wasn't one. One of us is wrong about that page, and I'm not yet sure it's the tool. I might have written my own key wrong. The eval was meant to check the tool. It checked me too.
I'm not fixing any of it here. The fixes are their own work, later. Today the result is the result. Three out of ten, written down before I touch anything, because the number only means something if I record it before I'm tempted to improve it.